
 zabbix警告常见问题集锦
zabbix警告常见问题集锦
一、磁盘
1、告警:Disk read/write request responses are too high
表达式解释为:
最近15分钟的对应磁盘的Disk read request avg waiting time (r_await)大于20ms或者 Disk write request avg waiting time (w_await) 大于20ms
min(/Linux block devices by Zabbix agent/vfs.dev.read.await[{#DEVNAME}],15m) > {KaTeX parse error: Expected '}', got '#' at position 27: …D.AWAIT.WARN:"{#̲DEVNAME}"} or m…VFS.DEV.WRITE.AWAIT.WARN:“{#DEVNAME}”}
解决方案
a、模板Linux block devices by Zabbix agent 中的提高宏 {KaTeX parse error: Expected 'EOF', got '}' at position 24: …READ.AWAIT.WARN}̲ 和 宏 {VFS.DEV.WRITE.AWAIT.WARN} 的值 默认是20。
b、上SSD系统盘、大容量数据盘。
c、以上两种方法只能解决提示,但解决为何读写高的问题才是根本。
# 查读写io进程
iotop
# 查io高的pid和进程
pidstat -d 1 10
二、数据库相关(Mysql,MariaDB)
1、告警:MySQL: Replication lag is too high (over 30m for 5m)
Seconds_Behind_Master时长超过1800秒,具体实际情况进行恢复主从延迟即可。
2、告警:MySQL: Buffer pool utilization is too low (less 50% for 5m)
由于分配了比实际需要更多的 RAM。结合实际情况,降低其严重性即可。
因为对存储服务器分配更多的RAM在合理计划范围内、增加缓冲池字节大小有利于提高性能。
Mysql官网innodb_buffer_pool_size参数详解
三、Zabbix Server相关
1、告警:More than 100 items having missing data for more than 10 minutes
为轮询器的数量不足以监控监控项
解决方案
StartPollers 轮询器实例数量。根据具体情况设置大小,默认为5
修改zabbix_server.conf中StartPollers=5为StartPollers=100。
2、告警:Zabbix poller processes more than 75% busy
unreachable poller processes 一直在处于busy的状态,那这个具体代表什么意思呢,查看官方文档zabbix internal process、unreachable poller - poller for unreachable devices 用于轮询不可到达到的设备。
可能情况:
通过Zabbix agent采集数据的设备处于moniting的状态但是此时机器死机或其他原因导致zabbix agent死掉server获取不到数据,此时unreachable poller就会升高。
通过Zabbix agent采集数据的设备处于moniting的状态但是server向agent获取数据时时间过长,经常超过server设置的timeout时间,此时unreachable poller就会升高。
支撑Zabbix的MySQL卡住了,Zabbix服务器的IO卡住了都有可能,Zabbix进程分配到内存不足都有可能。
一个简单的方法是增加Zabbix Server启动时初始化的进程数量,这样直接增加了轮询的负载量,从比例上来讲忙的情况就少了。
解决方案
CacheSize:缓存大小, 单位字节.用于存储主机、监控项、触发器数据的共享内存大小。 修改zabbix_server.conf中CacheSize=8M为CacheSize=2048M。
3、告警Zabbix server: Zabbix value cache working in low memory mode
解决方案
修改zabbix_server.conf配置的ValueCacheSize=2048M
四、Redis相关
1、告警:Redis: Memory fragmentation ratio is too high (over 1.5 in 15m)
内存碎片率:mem_fragmentation_ratio = used_memory_rss / used_memory
used_memory :Redis使用其分配器分配的内存大小
used_memory_rss :操作系统分配给Redis实例的内存大小,表示该进程所占物理内存的大小
两者包括了实际缓存占用的内存和Redis自身运行所占用的内存,used_memory_rss指标还包含了内存碎片的开销,内存碎片是由操作系统低效的分配/回收物理内存导致的。
mem_fragmentation_ratio < 1 表示Redis内存分配超出了物理内存,操作系统正在进行内存交换,内存交换会引起非常明显的响应延迟;
mem_fragmentation_ratio > 1 是合理的;
mem_fragmentation_ratio > 1.5 说明Redis消耗了实际需要物理内存的150%以上,其中50%是内存碎片率,可
内存碎片率略高于1是属于正常,但超出1.5的时候就说明redis的内存管理变差了
分析实际环境,因为该redis主要是存储频繁更新的数据,每次更新数据之前,redis会删除旧的数据,实际上,由于Redis释放了内存块,但内存分配器并没有返回内存给操作系统。
解决方案
开启碎片整理为redis.conf中,修改# activedefrag no为activedefrag yes。
# 开启碎片整理
activedefrag yes
# 当碎片达到 100mb 时,开启内存碎片整理
#active-defrag-ignore-bytes 100mb
# 当碎片超过 10% 时,开启内存碎片整理
#active-defrag-threshold-lower 10
# 内存碎片超过 100%,则尽最大努力整理
active-defrag-threshold-upper 100
# 内存自动整理占用资源最小百分比
active-defrag-cycle-min 25
# # 内存自动整理占用资源最大百分比
active-defrag-cycle-max 75
2、衍生问题①:开启内存碎片整理activedefrag yes报错(error)
ERR Active defragmentation cannot be enabled: it requires a Redis server compiled with a modified Jemalloc like the one shipped by default with the Redis source distribution
这个内存分配器是在编译时指定的,可以是libc、jemalloc或者tcmalloc。used_memory_rss会越来越大,导致mem_fragmentation_ratio越来越高
解决方案
因编译的时候内存分配器非jemalloc,需要重新使用jemalloc编译。编译以后问题解决。
3、衍生问题②:即使开启自动碎片整理后,仍然会告警。
解决方案
考虑提高阈值。
性能相关
4、告警:sda: Disk read/write request responses are too high (read > 20 ms for 15m or write > 20 ms for 15m)
装有Clickhouse服务器A1、A2、S1、S2磁盘写入等待时间高于默认20ms
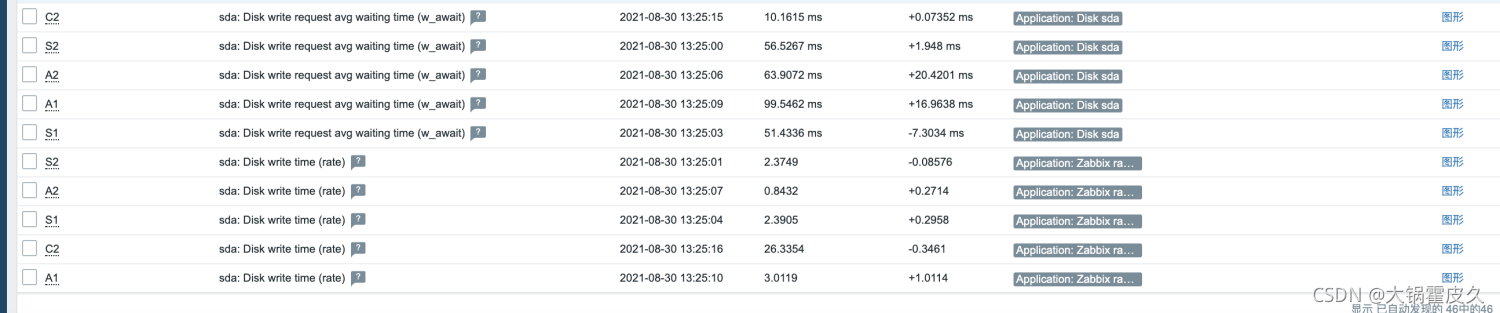
r_await:每个读操作平均所需的时间=[Δrd_ticks/Δrd_ios]
不仅包括硬盘设备读操作的时间,还包括了在kernel队列中等待的时间。
w_await:每个写操作平均所需的时间=[Δwr_ticks/Δwr_ios]
不仅包括硬盘设备写操作的时间,还包括了在kernel队列中等待的时间。
解决方案(暂未解决)
根据读r_await基本没有延迟。
可能是clikchouse数据库特性导致,考虑优化clickhouse配置。
或者修改连接clickhouse程序代码高频低量写入改为流式写入。


 |
|